Business Challenge
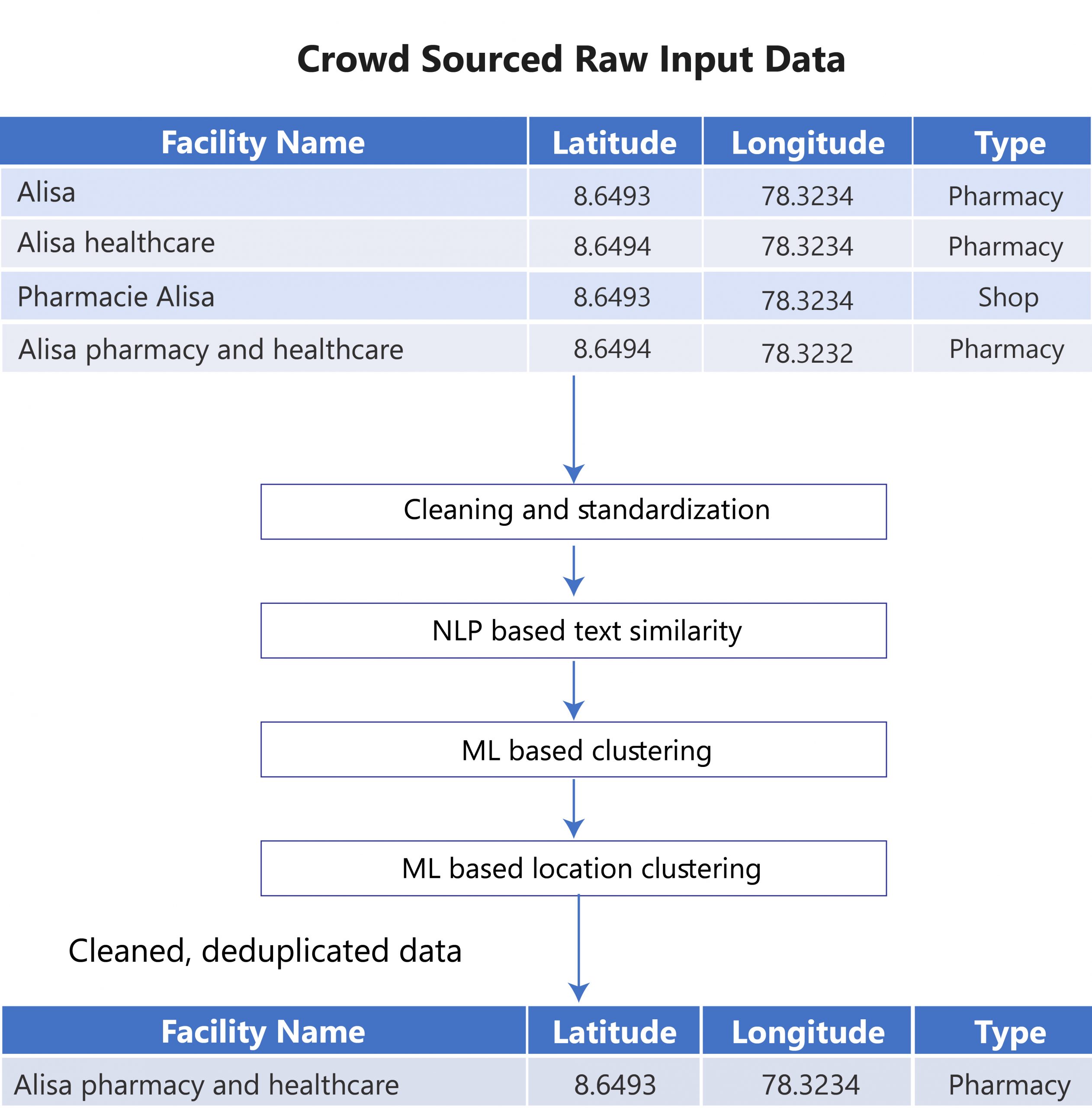
Our client had thousands of entries to health facility data with facility name, location (latitude/longitude), facility type, working hours, etc. The challenge was to know the unique data from numerous duplicate entries. We were to then eliminate the duplicate data. Using these details, our client wanted us to build a dashboard to bring out insights about the health facility situated in the city.
Approach and Solution
Our approach was to identify a similar name in a nearby location which would be a unique health facility. The first step was to decide if two words are similar or not based on Cosine Similarity and Hierarchical Clustering. Hierarchical Clustering helps to group similar names based on cosine similarity scores into the same cluster. Through DBSCAN, we determined whether two locations are very near to each other(same cluster or not) by considering a radius of 100m. If there are points less than or within 100m, then they will come under one cluster and whenever the distance between two points is more than 100 meters, then it will come under another cluster (adjacent clusters).
Benefits
- Around 16000 entries were passed through the algorithm which identified 2000 unique health facilities with accurate details.
- The method helped in identifying and eliminating duplicates thus improving the quality of data.
Network
Capacity Planing
Our client had thousands of servers spread across the globe carrying internet traffic. The main challenge was managing these servers at optimal utilization.
Vendor Contract Analytics
Our client had thousands of contract documents scanned and stored as pdf documents. Manually scouring through these documents...
CDN
Log Analytics
Our client receives a large number of crowd sourced images. They receive many pictures which are blurry and some of the images...